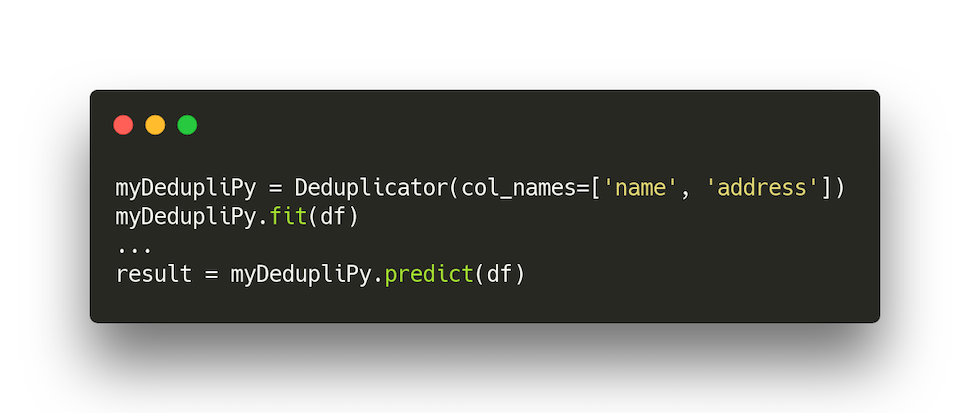
DedupliPy
Deduplication is the task to combine different representations of the same real world entity.
This Python package implements deduplication using active learning. Active learning allows for
rapid training without having to provide a large, manually labelled dataset.
DedupliPy is an end-to-end solution with advantages over existing solutions:
DedupliPy is an end-to-end solution with advantages over existing solutions:
- active learning; no large manually labelled dataset required
- during active learning, the user gets notified when the model converged and training may be finished
- works out of the box, advanced users can choose settings as desired (custom blocking rules, custom metrics, interaction features)